Analogous to sealed classes, sealed interfaces can also be defined. However, a sealed interface can have both subinterfaces and subclasses as its permitted direct subtypes. The permitted subtypes can be subclasses that implement the sealed interface and subinterfaces that extend the sealed interface. This is in contrast to a sealed class that can have direct subclasses, but not direct subinterfaces—as classes cannot be extended or implemented by interfaces.
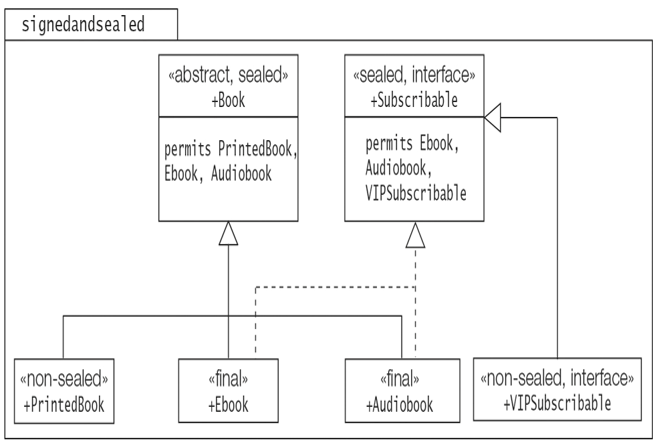
Figure 5.10 shows the book domain from Figure 5.9 that has been augmented with a sealed interface that specifies its permitted direct subtypes in a permits clause:
public sealed interface Subscribable permits Ebook, Audiobook, VIPSubcribable {}
The sealed superinterface Subscribable has two final permitted direct subclasses (that implement the superinterface) and one non-sealed direct subinterface (that extends the superinterface). The declarations of the permitted direct subclasses Ebook and Audiobook have been updated accordingly so that they implement the direct superinterface Subscribable.
public final class Ebook extends Book implements Subscribable {} public final class Audiobook extends Book implements Subscribable {} public non-sealed interface VIPSubcribable extends Subscribable {}
public abstract sealed class Book permits PrintedBook, Ebook, Audiobook {} public non-sealed class PrintedBook extends Book {}
Note that it is perfectly possible for a class or an interface to be a permitted direct subtype of more than one direct supertype—as is the case for the Ebook and the Audiobook subclasses in Figure 5.10.
Figure 5.10 Sealed Classes and Interfaces
We see from the discussion above that the permitted direct subtypes of a sealed superinterface abide by the same contract rules as for sealed superclasses:
A permitted direct subclass or subinterface must extend or implement its direct superinterface, respectively.
Any permitted subclass of a sealed interface must be declared either sealed, non-sealed or final, but any permitted subinterface can only be declared either sealed or non-sealed. The modifier final is not allowed for interfaces.
The same rules for locality also apply for sealed interfaces and their permitted direct subtypes: All are declared either in the same named module or in the same package (named or unnamed) in the unnamed module.
Enum and Record Types as Permitted Direct Subtypes
By definition, an enum type (p. 287) is either implicitly final (has no enum constants that have a class body, as shown at (2)) or implicitly sealed (has at least one enum constant with a class body that constitutes an implicitly declared direct subclass, as shown at (3) for the constant DVD_R that has an empty class body). Thus an enum type can be specified as a permitted direct subtype of a sealed superinterface, as shown at (1). The modifiers final and sealed cannot be explicitly specified in the enum type declaration.
sealed interface MediaStorage permits CD, DVD {} // (1) Sealed interface enum CD implements MediaStorage {CD_ROM, CD_R, CD_W} // (2) Implicitly final enum DVD implements MediaStorage {DVD_R {}, DVD_RW} // (3) Implicitly sealed
Analogously, a record class (p. 299) is implicitly final, and can be specified as a permitted direct subtype of a sealed superinterface. The sealed interface MediaStorage at (1a) now permits the record class HardDisk as a direct subtype. Again note that the modifier final cannot be specified in the header of the HardDisk record class declared at (4).
No access modifier implies package accessibility in this context. When no member access modifier is specified, the member is accessible only by other classes in the same package in which its class is declared. Even if its class is accessible in another package, the member is not accessible elsewhere. Package member access is more restrictive than protected member access.
In Example 6.8, the instance field pkgBool in an instance of the class Superclass1 has package access and is only accessible within pkg1, but not in any other packages— that is to say, it is accessible only by Client 1 and Client 2. Client 3 and Client 4 in pkg2 cannot access this field.
private Members
The private modifier is the most restrictive of all the access modifiers. Private members are not accessible by any other classes. This also applies to subclasses, whether they are in the same package or not. Since they are not accessible by their simple names in a subclass, they are also not inherited by the subclass. A standard design strategy for a class is to make all instance fields private and provide public get methods for such fields. Auxiliary methods are often declared as private, as they do not concern any client.
None of the clients in Figure 6.5 can access the private instance field privLong in an instance of the class Superclass1. This instance field is only accessible in the defining class—that is, in the class Superclass1.
Table 6.3 provides a summary of access modifiers for members in a class. References in parentheses refer to clients in Figure 6.5.
Table 6.3 Accessibility of Members in a Class (Non-Modular)
Member access
In the defining class Superclass1
In a subclass in the same package (Client 1)
In a non-subclass in the same package (Client 2)
In a subclass in a different package (Client 3)
In a non-subclass in a different package (Client 4)
public
Yes
Yes
Yes
Yes
Yes
protected
Yes
Yes
Yes
Yes
No
package
Yes
Yes
Yes
No
No
private
Yes
No
No
No
No
Additional Remarks on Accessibility
Access modifiers that can be specified for a class member apply equally to constructors. However, when no constructor is specified, the default constructor inserted by the compiler implicitly follows the accessibility of the class.
Accessibility of members declared in an enum type is analogous to those declared in a class, except for enum constants that are always public and constructors that are always private. A protected member in an enum type is only accessible in its own package, since an enum type is implicitly final. Member declarations in an enum type are discussed in §5.13, p. 290.
In contrast, the accessibility of members declared in an interface is always implicitly public (§5.6, p. 238). Omission of the public access modifier in this context does not imply package accessibility.
By specifying member access modifiers, a class can control which information is accessible to clients (i.e., other classes). These modifiers help a class define a contract so that clients know exactly which services are offered by the class.
The accessibility of a member in a class can be any one of the following:
public
protected
package access (also known as package-private and default access), when no access modifier is specified
private
In the following discussion of access modifiers for members of a class, keep in mind that the member access modifier has meaning only if the class (or one of its subclasses) is accessible to the client. Also, note that only one access modifier can be specified for a member.
The discussion in this subsection applies to both instance and static members of top-level classes.
In UML notation, when applied to member names the prefixes +, #, and – indicate public, protected, and private member access, respectively. No access modifier indicates package access for class members.
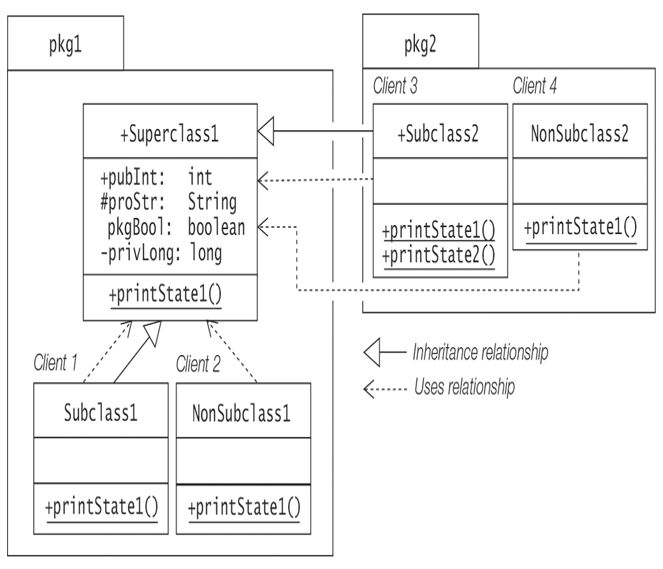
The package hierarchy shown in Figure 6.5 is implemented by the code in Example 6.8. The class Superclass1 at (1) in pkg1 has two subclasses: Subclass1 at (3) in pkg1 and Subclass2 at (5) in pkg2. The class Superclass1 in pkg1 is used by the other classes (designated as Client 1 to Client 4) in Figure 6.5.
Figure 6.5 Accessibility of Class Members
Accessibility of a member is illustrated in Example 6.8 by the four instance fields defined in the class Superclass1 in pkg1, where each instance field has a different accessibility. These four instance fields are accessed in a Superclass1 object created in the static method printState1() declared in five different contexts:
Defining class: The class in which the member is declared—that is, pkg1.Superclass1 in which the four instance fields being accessed are declared
Client 1: From a subclass in the same package—that is, pkg1.Subclass1
Client 2: From a non-subclass in the same package—that is, pkg1.NonSubclass1
Client 3: From a subclass in another package—that is, pkg2.Subclass2
Client 4: From a non-subclass in another package—that is, pkg2.NonSubclass2
Shared resources are typically implemented using synchronized code in order to guarantee thread safety of the shared resource (§22.4, p. 1387). However, if the shared resource is an immutable object, thread safety comes for free.
An object is immutable if its state cannot be changed once it has been constructed. Since its state can only be read, there can be no thread interference and the state is always consistent.
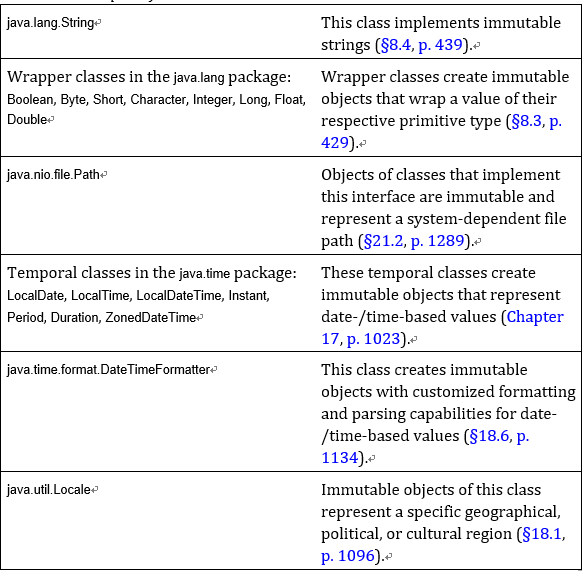
Some examples of immutable classes from the Java SE Platform API are listed in Table 6.5. Any method that seemingly modifies the state of an immutable object is in fact returning a new immutable object with the state modified appropriately based on the original object. Primitive values are of course always immutable.
Appointments(week 45):[5, 3, 8, 10, 7, 8, 9] Exception in thread “main” java.lang.IllegalArgumentException: Stats not for whole week: [10, 5, 20, 7] at WeeklyStats.<init>(WeeklyStats.java:14) at StatsClient.main(StatsClient.java:7)
There are certain guidelines that can help to avoid common pitfalls when implementing immutable classes. We will illustrate implementing an immutable class called WeeklyStats in Example 6.10, whose instances, once created, cannot be modified. The class WeeklyStats creates an object with weekly statistics of a specified entity.
It should not be possible to extend the class.
Caution should be exercised in extending an immutable class to prevent any subclass from subverting the immutable nature of the superclass.
A straightforward approach is to declare the class as final, as was done in Example 6.10 at (1) for the class WeeklyStats. Another approach is to declare the constructor as private and provide static factory methods to construct instances (discussed below). A static factory method is a static method whose sole purpose is to construct and return a new instance of the class—an alternative to calling the constructor directly.
All fields should be declared final and private.
Declaring the fields as private makes them accessible only inside the class, and other clients cannot access and modify them. This is the case for the fields in the WeeklyStats class at (2), (3), and (4).
Declaring a field as final means the value stored in the field cannot be changed once initialized. However, if the final field is a reference to an object, the state of this object can be changed by other clients who might be sharing this object, unless the object is also immutable. See the last guideline on how to safeguard the state of an mutable object referenced by a field.
Check the consistency of the object state at the time the object is created.
Since it is not possible to change the state of an immutable object, the state should be checked for consistency when the object is created. If all relevant information to initialize the object is available when it is created, the state can be checked for consistency and any necessary measures taken. For example, a suitable exception can be thrown to signal illegal arguments.
In the class WeeklyStats, the constructor at (5) is passed all the necessary values to initialize the object, and it checks whether they will result in a legal and consistent state for the object.
No set methods (a.k.a. setter or mutator methods) should be provided.
Set methods that change values in fields or objects referenced by fields should not be permitted. The class WeeklyStats does not have any set methods, and only provides get methods (a.k.a. getter or assessor methods).
If a setter method is necessary, then the method should create a new instance of the class based on the modified state, and return that to the client, leaving the original instance unmodified. This approach has to be weighed against the cost of creating new instances, but is usually offset by other advantages associated with using immutable classes, like thread safety without synchronized code. Caching frequently used objects can alleviate some overhead of creating new objects, as exemplified by the immutable wrapper classes for primitive types. For example, the Boolean class has a static factory method valueOf() that always returns one of two objects, Boolean.TRUE or Boolean.FALSE, depending on whether its boolean argument was true or false, respectively. The Integer class interns values between –128 and 127 for efficiency so that there is only one Integer object to represent each int value in this range.
A client should not be able to access mutable objects referred to by any fields in the class.
The class should not provide any methods that can modify its mutable objects. The class WeeklyStats complies with this requirement.
A class should also not share references to its mutable objects. The field at (4) has the type array of int that is mutable. An int array is passed as a parameter to the constructor at (5). The constructor in this case makes its own copy of this int array, so as not to share the array passed as an argument by the client. The getWeeklyStats() method at (8) does not return the reference value of the int array stored in the field stats. It creates and returns a new int array with values copied from its private int array. This technique is known as defensive copying. This way, the class avoids sharing references of its mutable objects with clients.
The class declaration below illustrates another approach to prevent a class from being extended. The class WeeklyStats is no longer declared final at (1), but now has a private constructor. This constructor at (5a) cannot be called by any client of the class to create an object. Instead, the class provides a static factory method at (5b) that creates an object by calling the private constructor. No subclass can be instantiated, as the superclass private constructor cannot be called, neither directly nor implicitly, in a subclass constructor.
public class WeeklyStatsV2 { // (1) Class is not final. … private WeeklyStatsV2(String description, int weekNumber, int[] stats) { // (5a) Private constructor this.description = description; this.weekNumber = weekNumber; this.stats = Arrays.copyOf(stats, stats.length); // Create a private copy. } // (5b) Static factory method to construct objects. public static WeeklyStatsV2 getNewWeeklyStats(String description, int weekNumber, int[] stats) { if (weekNumber <= 0 || weekNumber > 52) { throw new IllegalArgumentException(“Invalid week number: ” + weekNumber); } if (stats.length != 7) { throw new IllegalArgumentException(“Stats not for whole week: ” + Arrays.toString(stats)); } return new WeeklyStatsV2(description, weekNumber, stats); } … }
A class having just static methods is referred to as a utility class. Such a class cannot be instantiated and has no state, and is thus immutable. Examples of such classes in the Java API include the following: the java.lang.Math class, the java.util.Collections class, the java.util.Arrays class, and the java.util.concurrent.Executors class.
Apart from being thread safe, immutable objects have many other advantages. Once created, their state is guaranteed to be consistent throughout their lifetime. That makes them easy to reason about. Immutable classes are relatively simple to construct, amenable to testing, and easy to use compared to mutable classes. There is hardly any need to make or provide provisions for making copies of such objects. Their hash code value, once computed, can be cached for later use, as it will never change. Because of their immutable state, they are ideal candidates for keys in maps, and as elements in sets. They also are ideal building blocks for new and more complex objects.
A downside of using an immutable object is that if a value must be changed in its state, then a new object must be created, which can be costly if object construction is expensive.
A program typically uses other precompiled classes and libraries, in addition to the ones provided by the Java standard libraries. In order for the JDK tools to find these files efficiently, the CLASSPATH environment variable or the -classpath option can be used, both of which are explained below.
In particular, the CLASSPATH environment variable can be used to specify the class search path (usually abbreviated to just class path), which is the pathnames or locations in the file system where JDK tools should look when searching for third-party and user-defined classes. Alternatively, the -classpath option (short form -cp) of the JDK tool commands can be used for the same purpose. The CLASSPATH environment variable is not recommended for this purpose, as its class path value affects all Java applications on the host platform, and any application can modify it. However, the -classpath option can be used to set the class path for each application individually. This way, an application cannot modify the class path for other applications. The class path specified in the -classpath option supersedes the path or paths set by the CLASSPATH environment variable while the JDK tool command is running. We will not discuss the CLASSPATH environment variable here, and will assume it to be undefined.
Basically, the JDK tools first look in the directories where the Java standard libraries are installed. If the class is not found in the standard libraries, the tool searches in the class path. When no class path is defined, the default value of the class path is assumed to be the current directory. If the -classpath option is used and the current directory should be searched by the JDK tool, the current directory must be specified as an entry in the class path, just like any other directory that should be searched. This is most conveniently done by including ‘.’ as one of the entries in the class path.
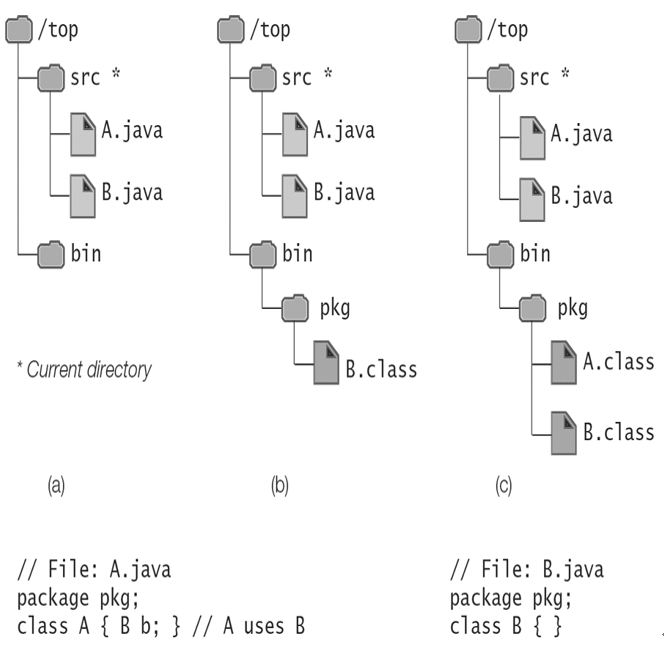
We will use the file hierarchies shown in Figure 6.4 to illustrate some of the intricacies involved when searching for classes. The current directory has the absolute pathname /top/src, where the source files are stored. The package pkg will be created under the directory with the absolute pathname /top/bin. The source code in the two source files A.java and B.java is also shown in Figure 6.4.
Figure 6.4 Searching for Classes
The file hierarchy before any files are compiled is shown in Figure 6.4a. Since the class B does not use any other classes, we compile it first with the following command, resulting in the file hierarchy shown in Figure 6.4b:
>javac -d ../bin B.java
Next, we try to compile the file A.java, and we get the following results:
Declarations and statements can be grouped into a block using curly brackets, {}. Blocks can be nested, and scope rules apply to local variable declarations in such blocks. A local declaration can appear anywhere in a block. The general rule is that a variable declared in a block is in scope in the block in which it is declared, but it is not accessible outside this block. It is not possible to redeclare a variable if a local variable of the same name is already declared in the current scope.
Local variables of a method include the formal parameters of the method and variables that are declared in the method body. The local variables in a method are created each time the method is invoked, and are therefore distinct from local variables in other invocations of the same method that might be executing (§7.1, p. 365).
Figure 6.6 illustrates block scope (also known as lexical scope) for local variables. It shows four blocks: Block 1 is the body of the method main(), Block 2 is the body of the for(;;) loop, Block 3 is the body of a switch statement, and Block 4 is the body of an if statement.
Parameters cannot be redeclared in the method body, as shown at (1) in Block 1.
A local variable—already declared in an enclosing block, and therefore visible in a nested block—cannot be redeclared in the nested block. These cases are shown at (3), (5), and (6).
A local variable in a block can be redeclared in another block if the blocks are disjoint—that is, they do not overlap. This is the case for variable i at (2) in Block 3 and at (4) in Block 4, as these two blocks are disjoint.
The scope of a local variable declaration begins from where it is declared in the block and ends where this block terminates. The scope of the loop variable index is the entire Block 2. Even though Block 2 is nested in Block 1, the declaration of the variable index at (7) in Block 1 is valid. The scope of the variable index at (7) spans from its declaration to the end of Block 1, and it does not overlap with that of the loop variable index in Block 2.
7.1 Stack-Based Execution and Exception Propagation
The exception mechanism is built around the throw-and-catch paradigm. To throw an exception is to signal that an unexpected event has occurred. To catch an exception is to take appropriate action to deal with the exception. An exception is caught by an exception handler, and the exception need not be caught in the same context in which it was thrown. The runtime behavior of the program determines which exceptions are thrown and how they are caught. The throw-and-catch principle is embedded in the try-catch-finally construct (p. 375).
Several threads can be executing at the same time in the JVM (§22.2, p. 1369). Each thread has its own JVM stack (also called a runtime stack, call stack, or invocation stack in the literature) that is used to handle execution of methods. Each element on the stack is called an activation frame or a stack frame and corresponds to a method call. Each new method call results in a new activation frame being pushed on the stack, which stores all the pertinent information such as the local variables. The method with the activation frame on the top of the stack is the one currently executing. When this method finishes executing, its activation frame is popped from the top of the stack. Execution then continues in the method corresponding to the activation frame that is now uncovered on the top of the stack. The methods on the stack are said to be active, as their execution has not completed. At any given time, the active methods on a JVM stack make up what is called the stack trace of a thread’s execution.
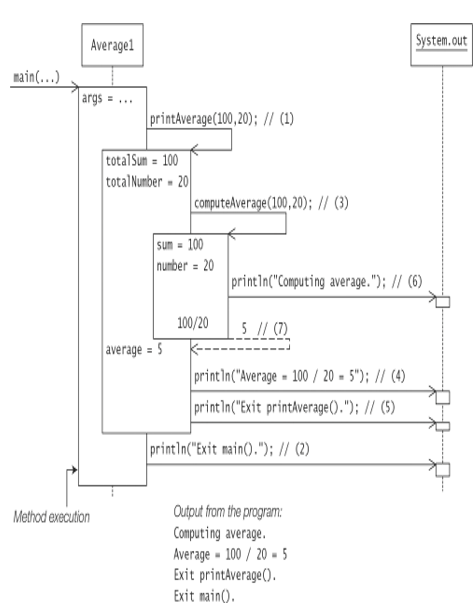
Example 7.1 is a simple program to illustrate method execution. It calculates the average for a list of integers, given the sum of all the integers and the number of integers. It uses three methods:
The method main() calls the method printAverage() with parameters supplying the total sum of the integers and the total number of integers, (1).
The method printAverage() in turn calls the method computeAverage(), (3).
The method computeAverage() uses integer division to calculate the average and returns the result, (7).
Execution of Example 7.1 is illustrated in Figure 7.1. Each method execution is shown as a box with the local variables declared in the method. The height of the box indicates how long a method is active. Before the call to the method System.out.println() at (6) in Figure 7.1, the stack trace comprises the three active methods: main(), printAverage(), and computeAverage(). The result 5 from the method computeAverage() is returned at (7) in Figure 7.1. The output from the program corresponds with the sequence of method calls in Figure 7.1. As the program terminates normally, this program behavior is called normal execution.
Computing average. Exception in thread “main” java.lang.ArithmeticException: / by zero at Average1.computeAverage(Average1.java:18) at Average1.printAverage(Average1.java:10) at Average1.main(Average1.java:5)
Figure 7.2 illustrates the program execution when the method printAverage() is called with the arguments 100 and 0 at (1). All goes well until the return statement at (7) in the method computeAverage() is executed. An error event occurs in calculating the expression sum/number because integer division by 0 is an illegal operation. This event is signaled by the JVM by throwing an ArithmeticException (p. 372). This exception is propagated by the JVM through the JVM stack as explained next.
Figure 7.1 Normal Method Execution
Figure 7.2 illustrates the case where an exception is thrown and the program does not take any explicit action to deal with the exception. In Figure 7.2, execution of the computeAverage() method is suspended at the point where the exception is thrown. The execution of the return statement at (7) never gets completed. Since this method does not have any code to deal with the exception, its execution is likewise terminated abruptly and its activation frame popped. We say that the method completes abruptly. The exception is then offered to the method whose activation is now on the top of the stack (printAverage()). This method does not have any code to deal with the exception either, so its execution completes abruptly. The statements at (4) and (5) in the method printAverage() never get executed. The exception now propagates to the last active method (main()). This does not deal with the exception either. The main() method also completes abruptly. The statement at (2) in the main() method never gets executed. Since the exception is not caught by any of the active methods, it is dealt with by the main thread’s default exception handler. The default exception handler usually prints the name of the exception, with an explanatory message, followed by a printout of the stack trace at the time the exception was thrown. An uncaught exception, as in this case, results in the death of the thread in which the exception occurred.
Figure 7.2 Exception Propagation
If an exception is thrown during the evaluation of the left-hand operand of a binary expression, then the right-hand operand is not evaluated. Similarly, if an exception is thrown during the evaluation of a list of expressions (e.g., a list of actual parameters in a method call), evaluation of the rest of the list is skipped.
If the line numbers in the stack trace are not printed in the output as shown previously, use the following command to run the program:
The compiler cannot find the class B—that is, the file B.class containing the Java bytecode for the class B. In Figure 6.4b, we can see that it is in the package pkg under the directory bin, but the compiler cannot find it. This is hardly surprising, as there is no bytecode file for the class B in the current directory, which is the default value of the class path. The following command sets the value of the class path to be /top/bin, and compilation is successful (Figure 6.4c):
It is very important to understand that when we want the JDK tool to search in a named package, it is the location or the root of the package that is specified; in other words, the class path indicates the directory that contains the first component of the fully qualified package name. In Figure 6.4c, the package pkg is contained under the directory whose absolute path is /top/bin. The following command will not work, as the directory /top/bin/pkg does not contain a package with the name pkg that has a class B:
Also, the compiler is not using the class path to find the source file(s) that are specified in the command line. In the preceding command, the source file has the relative pathname ./A.java. Consequently, the compiler looks for the source file in the current directory. The class path is used to find the classes used by the class A, in this case, to find class B.
Given the file hierarchy in Figure 6.3, the following -classpath option sets the class path so that all packages (wizard.pandorasbox, wizard.pandorasbox.artifacts, wizard.spells) in Figure 6.3 will be searched, as all packages are located under the specified directory:
-classpath /pgjc/work
However, the following -classpath option will not help in finding any of the packages in Figure 6.3, as none of the packages are located under the specified directory:
This command also illustrates an important point about package names: The fully qualified package name should not be split. The package name for the class wizard.pandorasbox.Clown is wizard.pandorasbox, and must be specified fully. The following command will search all packages in Figure 6.3 for classes that are used by the class wizard.pandorasbox.Clown:
The class path can specify several entries (i.e., several locations), and the JDK tool searches them in the order they are specified, from left to right.
We have used the path-separator character ‘:’ for Unix-based platforms to separate the entries, and also included the current directory (.) as an entry. There should be no whitespace on either side of the path-separator character. On the Windows platform, the path-separator character is a semicolon (;).
The search in the class path entries stops once the required class file is found. Therefore, the order in which entries are specified can be significant. If a class B is found in a package pkg located under the directory /ext/lib1, and also in a package pkg located under the directory /ext/lib2, the order in which the entries are specified in the two -classpath options shown below is significant. They will result in the class pkg.B being found under /ext/lib1 and /ext/lib2, respectively.
The examples so far have used absolute pathnames for class path entries. We can, of course, use relative pathnames as well. If the current directory has the absolute pathname /pgjc/work in Figure 6.3, the following command will search the packages under the current directory:
If the name of an entry in the class path includes whitespace, the name should be double-quoted so that it will be interpreted correctly:
-classpath “../new bin”
Table 6.1 summarizes the commands and options to compile and execute non-modular code. The tool documentation from Oracle provides more details on how to use the JDK development tools.
Table 6.1 Compiling and Executing Non-Modular Java Code
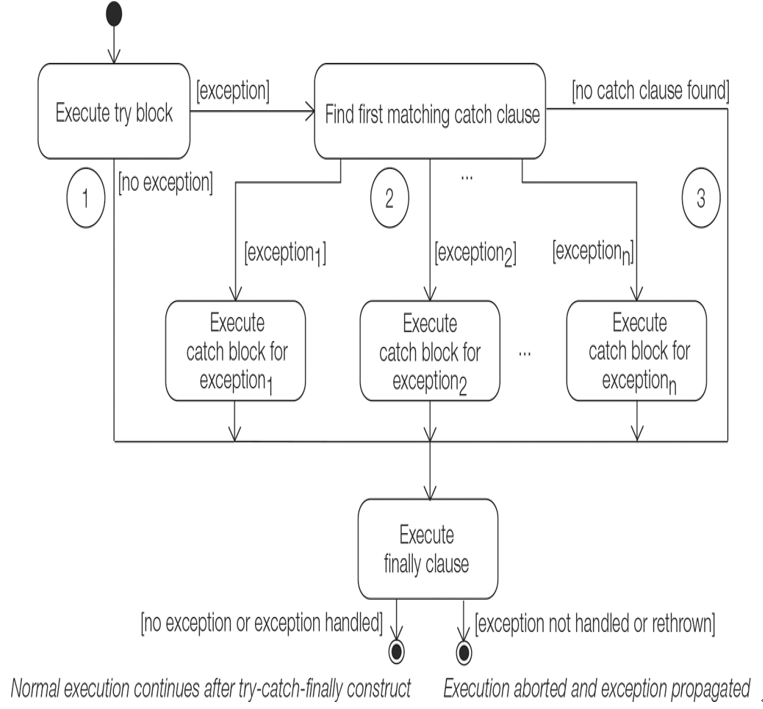
Only an exit from a try block resulting from an exception can transfer control to a catch clause. A catch clause can catch the thrown exception only if the exception is assignable to the parameter in the catch clause. The code of the first such catch clause is executed, and all other catch clauses are ignored.
On exit from a catch clause, normal execution continues unless there is any uncaught exception that has been thrown and not handled. If this is the case, the method is aborted after the execution of any finally clause and the exception propagated up the JVM stack.
It is important to note that after a catch clause has been executed, control is always transferred to the finally clause if one is specified. This is true as long as there is a finally clause, regardless of whether the catch clause itself throws an exception.
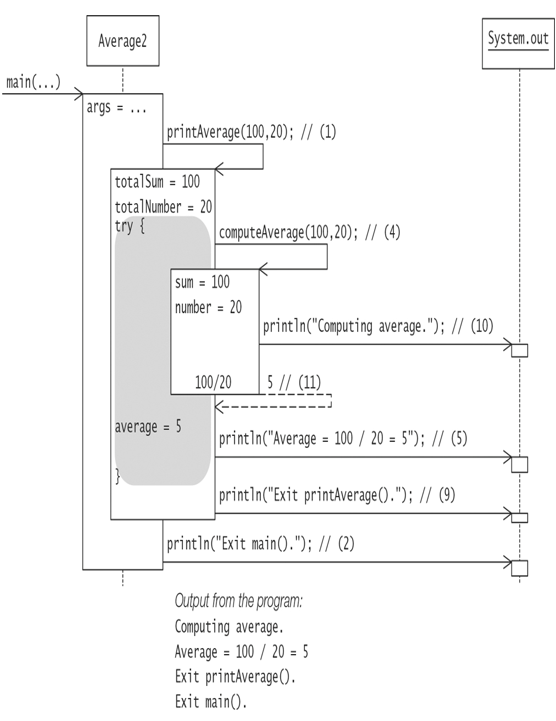
In Example 7.2, the method printAverage() calls the method computeAverage() in a try-catch construct at (4). The catch clause is declared to catch exceptions of type ArithmeticException. The catch clause handles the exception by printing the stack trace and some additional information at (7) and (8), respectively. Normal execution of the program is illustrated in Figure 7.5, which shows that the try block is executed but no exceptions are thrown, with normal execution continuing after the try-catch construct. This corresponds to Scenario 1 in Figure 7.4.
Computing average. java.lang.ArithmeticException: / by zero at Average2.computeAverage(Average2.java:23) at Average2.printAverage(Average2.java:11) at Average2.main(Average2.java:5) Exception handled in printAverage(). Exit printAverage(). Exit main().
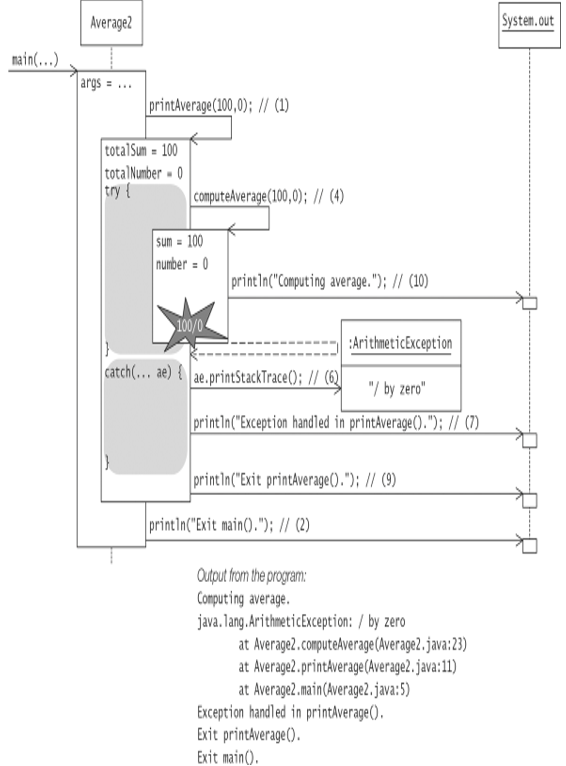
However, if we run the program in Example 7.2 with the following call at (1):
printAverage(100, 0)
an ArithmeticException is thrown by the integer division operator in the method computeAverage(). In Figure 7.6 we see that the execution of the method compute-Average() is stopped and the exception propagated to method printAverage(), where it is handled by the catch clause at (6). Normal execution of the method continues at (9) after the try-catch construct, as witnessed by the output from the statements at (9) and (2). This corresponds to Scenario 2 in Figure 7.4.
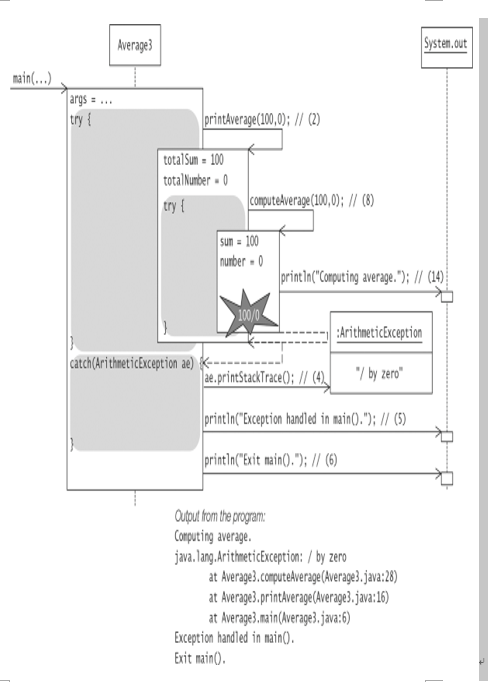
In Example 7.3, the main() method calls the printAverage() method in a try-catch construct at (1). The catch clause at (3) is declared to catch exceptions of type ArithmeticException. The printAverage() method calls the computeAverage() method in a try-catch construct at (7), but here the catch clause is declared to catch exceptions of type IllegalArgumentException. Execution of the program is illustrated in Figure 7.7, which shows that the ArithmeticException is first propagated to the catch clause in the printAverage() method. Because this catch clause cannot handle this exception, it is propagated further to the catch clause in the main() method, where it is caught and handled. Normal execution continues at (6) after the exception is handled.
In Example 7.3, the execution of the try block at (7) in the printAverage() method is never completed: The statement at (9) is never executed. The catch clause at (10) is skipped. The execution of the printAverage() method is aborted: The statement at (13) is never executed, and the exception is propagated. This corresponds to Scenario 3 in Figure 7.4.
Computing average. java.lang.ArithmeticException: / by zero at Average3.computeAverage(Average3.java:28) at Average3.printAverage(Average3.java:16) at Average3.main(Average3.java:6) Exception handled in main(). Exit main().
The scope of the exception parameter name in the catch clause is the body of the catch clause—that is, it is a local variable in the body of the catch clause. As mentioned earlier, the type of the exception object must be assignable to the type of the argument in the catch clause. In the body of the catch clause, the exception object can be queried like any other object by using the parameter name.
The javac compiler complains if a catch clause for a superclass exception shadows the catch clause for a subclass exception, as the catch clause of the subclass exception will never be executed (a situation known as unreachable code). The following example shows incorrect order of the catch clauses at (1) and (2), which will result in a compile-time error at (2): The superclass Exception will shadow the subclass ArithmeticException.
The compiler will also flag an error if the parameter of the catch clause has a checked exception type that cannot be thrown by the try block, as this would result in unreachable code.
A few aspects about the syntax of this construct should be noted. For each try block, there can be zero or more catch clauses (i.e., it can have multiple catch clauses), but only one finally clause. The catch clauses and the finally clause must always appear in conjunction with a try block, and in the right order. A try block must be followed by at least one catch clause, or a finally clause must be specified—in contrast to the try-with-resources statement where neither a catch nor a finally clause is mandatory (p. 407). In addition to the try block, each catch clause and the finally clause specify a block, { }. The block notation is mandatory.
Exceptions thrown during execution of the try block can be caught and handled in a catch clause. Each catch clause defines an exception handler. The header of the catch clause specifies exactly one exception parameter. The exception type must be of the Throwable class or one of its subclasses; otherwise, the code will not compile. The type of the exception parameter of a catch clause is specified by a single exception type in the syntax shown earlier, and such a catch clause is called a uni-catch clause.
A finally clause is always executed, regardless of the cause of exit from the try block, or whether any catch clause was executed at all. The two exceptions to this scenario are if the JVM crashes or the System.exit() method is called. Figure 7.4 shows three typical scenarios of control flow through the try-catch-finally construct.
Figure 7.4 The try-catch-finally Construct
The try block, the catch clause, and the finally clause of a try-catch-finally construct can contain arbitrary code, which means that a try-catch-finally construct can be nested in any block of the try-catch-finally construct. However, such nesting can easily make the code difficult to read and is best avoided, if possible.